Visualizando Seinfeld com ggplot2
Introdução
O ggplot2 é um pacote de visualização de dados open-source desenvolvido para o R. Criado por Hadley Wickham em 2005, é hoje uma das principais ferramentas de um cientista de dados.

Neste artigo não tenho a pretenção de ensinar a criar visualizações com o ggplot2 (uma boa fonte é o excelente livro R for Data Science), mas apenas mostrar alguns dos tipos de visualizações que podem ser criadas com o pacote. Para tanto, vamos utilizar alguns dados publicamente disponíveis sobre a série de TV Seinfeld.

Seinfeld foi uma série de comédia bastante longeva e de muito sucesso na TV americana. Tendo estreiado em julho de 1989, a série foi exibida por 9 temporadas, sem os altos e baixos típicos das séries longas.
Para entender um pouco do sucesso da série, vamos analisar as notas dadas a cada episódio pelos usuários do Internet Movie Database (IMDb), o mais famoso site de informações sobre cinema, TV, jogos e outras áreas de entretenimento. Como exemplo, a página episódio 11 da quarta temporada de Seinfeld mostra que cerca de 6400 usuários deram uma nota média de 9,5, uma das mais altas de todo a série.
Dados Utilizados
Mas antes de começarmos, vamos carregar os principais pacotes utilizados ao longo da análise:
Agora podemos carregar os dados disponíveis sobre as notas de Seinfeld no IMDb. Eles estão disponíveis em vários locais da internet, mas estes dados foram baixados especificamente do Kangle aqui.
Podemos ver abaixo que o banco de dados contém 172 linhas (episódios), com 7 variáveis: temporada, título do episódio, data da primeira transmissão na tv, nota média no IMDb, a quantidade de usuários que votaram no episódio, a sinópse do episódio e uma variável que indica o número do episódio.
df %>%
head() %>%
knitr::kable()| Season | Title | Airdate | Rating | Vote_count | Description | episode |
|---|---|---|---|---|---|---|
| 1 | Good News, Bad News | 5 Jul. 1989 | 7.6 | 3431 | Jerry and George argue whether an overnight visitor Jerry is expecting is coming with romantic intentions. | 1 |
| 1 | The Stakeout | 31 May 1990 | 7.7 | 2749 | Jerry and George stake out the lobby of an office building to find a woman Jerry met at a party but whose name and phone number he didn’t get. | 2 |
| 1 | The Robbery | 7 Jun. 1990 | 7.6 | 2496 | After Jerry’s apartment is robbed, Jerry starts to look for other apartments. But Jerry and George both want the same apartment, and Elaine wants the apartment of whoever loses out. | 3 |
| 1 | Male Unbonding | 14 Jun. 1990 | 7.4 | 2465 | Jerry tries various excuses to avoid meeting with an old friend with whom he no longer shares any interests. | 4 |
| 1 | The Stock Tip | 21 Jun. 1990 | 7.5 | 2352 | Jerry becomes apprehensive when he and George buy stock and the price falls while the person who suggested the stock is in hospital and can’t tell them when to sell. | 5 |
| 2 | The Ex-Girlfriend | 23 Jan. 1991 | 7.7 | 2261 | After George breaks up with his girlfriend, Jerry decides that he wants to see her. | 6 |
Abaixo, vemos algumas informações sobre a série. Mesmo permanecido por tanto tempo na TV (9 temporadas e mais de 170 episódios), a série conseguiu manter uma qualidade consistente ao longo do tempo, alcançando uma nota média de 8,4 IMDb.
df %>%
mutate(Airdate = lubridate::dmy(Airdate)) %>%
summarise(`Nota Média` = round(mean(Rating),1),
`Primeiro Episódio` = min(Airdate),
`Último Episódio` = max(Airdate),
`Temporadas` = max(Season),
`Episódios` = n()) %>%
knitr::kable()| Nota Média | Primeiro Episódio | Último Episódio | Temporadas | Episódios |
|---|---|---|---|---|
| 8.4 | 1989-07-05 | 1998-05-14 | 9 | 172 |
Mesmo com uma avaliação média tão elevada, é possível imaginar que a série passou por altos e baixos, tendo produzido episódios inesquecíveis, e outros nem tanto. Assim, vamos usar o ggplot2para analisar o desempenho da série ao longo dos seus 9 anos de exibição.
Gráficos de Classificação
Podemos começar calculando a nota média por temporada. E se o objetivo é encontrar as temporadas com melhor temporada, podemos usar gráficos de classificação como os de barra (geom_bar) ou sua versão mais atraente, o lollipop.
Gráfico de barras
df %>%
group_by(Season) %>%
summarise(nota_media = mean(Rating)) %>%
ggplot(aes(x = as.factor(Season), y = nota_media, color = as.factor(Season))) +
geom_point(size = 8) +
geom_segment(aes(x=as.factor(Season), xend=as.factor(Season), y=0, yend=nota_media),
size = 4) +
#geom_hline(yintercept = mean(df$Rating), linetype = 5, color = "grey10", size = 1) +
theme_ipsum(base_family = "Roboto", base_size = 22) +
labs(title = "Seinfeld, Nota Média por Temporada", y = "Nota Média", x = "Temporada",
caption = "Fonte: IMDb") +
geom_label(aes(label = round(nota_media, 1)), nudge_y = 2.0) +
theme(legend.position = "none") +
coord_flip()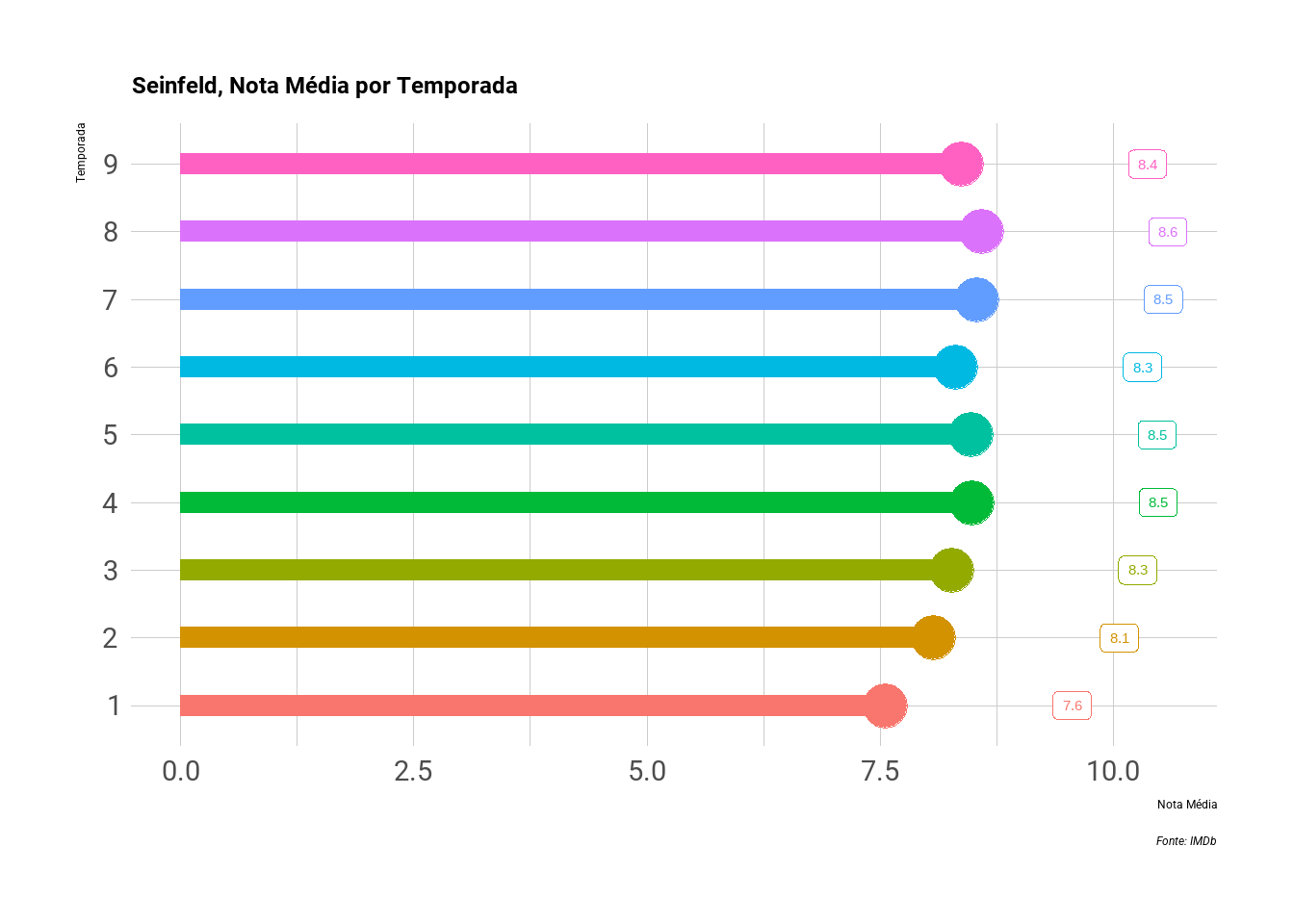 A série começou bastante desacreditada, com apenas 5 episódios sendo encomendados para sua primeira temporada, e apesar de um início abaixo da média, as temporadas seguintes elevaram o nível da série, com notas médias sempre acima de 8,0.
A série começou bastante desacreditada, com apenas 5 episódios sendo encomendados para sua primeira temporada, e apesar de um início abaixo da média, as temporadas seguintes elevaram o nível da série, com notas médias sempre acima de 8,0.
Gráfico de Nuvens
Outra forma de classificar informação é utilizando gráficos em nuvens. Este tipo de visualização é útil quando queremos mostrar a frequência com que palavras aparecem em textos.
Aqui vamos precisar contar o número de palavras na sinopse dos episódios. Para isso, podemos utilizar a função unnest_tokens do pacote tidytext, que permite separar as colunas de textos (Description, no nosso caso) em uma tabela de palavras (uma linha por palavra).
Quando trabalhamos com texto, é sempre boa prática eliminar aquelas palavras vazias, que não adicionam nenhum tipo de informação (the, in, on, if, when, etc). Para tanto, utilizamos o anti_join(stop_words).
needs::needs(tidytext, wordcloud2)
palavras_seinfeld <- df %>%
unnest_tokens(word, Description) %>%
anti_join(stop_words) %>%
mutate(word = str_replace(word, "\'s", "")) %>%
count(word, sort = TRUE)
palavras_seinfeld %>% head() %>% knitr::kable()| word | n |
|---|---|
| jerry | 195 |
| george | 163 |
| elaine | 138 |
| kramer | 109 |
| girlfriend | 43 |
| decides | 23 |
Como esperado, as palavras mais comuns nas sinopses dos episódios são os nomes dos quatro personagens principais da série: Jerry, George, Elaine e Kramer. Vamos ignora-las e exibir as demais palavras mais comuns:
set.seed(123)
palavras_seinfeld %>%
filter(!word %in% c("jerry", "george","elaine", "kramer")) %>%
wordcloud2(size = 1.6, backgroundColor = "black")Susan (19 menções) é uma importante personagem secundária na série, assim como Newman (14 menções). A palavra “decide” surge 23 vezes, indicando que vários episódios giram em torno de personagens tomando algum tipo de atitude. “Woman” surge 19 vezes, em razão dos vários episódios onde Jerry e George tentam encontrar o amor das suas vidas. Outra palavra bastante citada é “job”, provavelmente relacionada aos episódios onde George busca um emprego.
A sinópse é bastante interessante, mas estamos perdendo informações cruciais sobre a série nos baseando apenas nelas. Vamos mais fundo na análise de Seinfeld utilizando uma base de dados de todas as falas dos personagens ao longo da série. A base de scripts (que pode ser encontrada aqui) ofecece cada dialogo falado por cada personagem em todos em cada episódio da série.
script <- read_csv("scripts.csv.zip") %>% select(-X1)
script %>% head(2) %>% knitr::kable()| Character | Dialogue | EpisodeNo | SEID | Season |
|---|---|---|---|---|
| JERRY | Do you know what this is all about? Do you know, why were here? To be out, this is out…and out is one of the single most enjoyable experiences of life. People…did you ever hear people talking about We should go out? This is what theyre talking about…this whole thing, were all out now, no one is home. Not one person here is home, were all out! There are people tryin to find us, they dont know where we are. (on an imaginary phone) Did you ring?, I cant find him. Where did he go? He didnt tell me where he was going. He must have gone out. You wanna go out you get ready, you pick out the clothes, right? You take the shower, you get all ready, get the cash, get your friends, the car, the spot, the reservation…Then youre standing around, whatta you do? You go We gotta be getting back. Once youre out, you wanna get back! You wanna go to sleep, you wanna get up, you wanna go out again tomorrow, right? Where ever you are in life, its my feeling, youve gotta go. | 1 | S01E01 | 1 |
| JERRY | (pointing at Georges shirt) See, to me, that button is in the worst possible spot. The second button literally makes or breaks the shirt, look at it. Its too high! Its in no-mans-land. You look like you live with your mother. | 1 | S01E01 | 1 |
Acima, vemos a primeira aparição de Jerry Seinfeld, no show que leva seu nome, contando alguma piada sobre roupas em dos seus shows de stand-up. O resto da base representam mais de 54 mil dialogos trocados entre os múltiplos personagens que passaram pela história da série.
script %>%
summarise(`Total de falas` = n(),
`Total de Personagens` = n_distinct(Character))## # A tibble: 1 x 2
## `Total de falas` `Total de Personagens`
## <int> <int>
## 1 54616 1629Para tornar o gráfico de nuvens mais interessante, vamos gerar a núvem para um dos personagens principais: Elaine. Para tornar a visualização mais fácil, vamos limitar apenas para palavras mencionadas mais de 40 vezes.
nuvem_personagem <- function(personagem = "JERRY") {
palavras <- script %>%
filter(Character == personagem) %>%
unnest_tokens(word, Dialogue) %>%
anti_join(stop_words, by = "word") %>%
mutate(word = str_replace(word, "\'s", "")) %>%
count(word, sort = TRUE) %>%
filter(!word %in% c("Yeah", "Ah", "Uh",
"yeah", "hey", "ya", "gotta", "gonna","didnt",
"alright", "youre", "im", "ah", "wanna", "ive")) %>%
filter(n > 40)
palavras %>%
wordcloud2(size = 1.6, backgroundColor = "black")
}
nuvem_elaine <- nuvem_personagem("ELAINE")
saveWidget(nuvem_elaine,"tmp.html",selfcontained = F)
webshot::webshot("tmp.html","elaine.png", delay =5, vwidth = 480, vheight=480)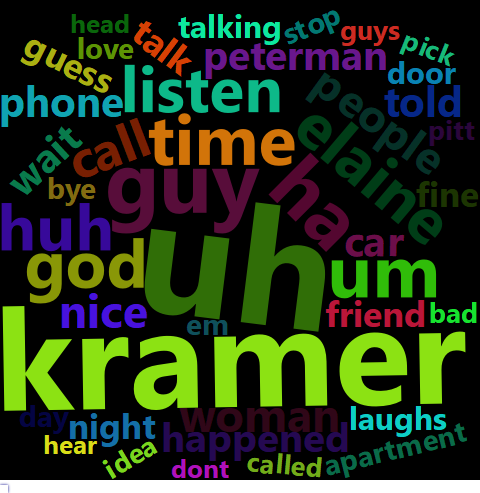
(Por alguma razão wordclou2 tem um bug bem estranho que não permite a visualização de mais que uma núvem na mesma página. Por isso, essas últimas visualizações são estáticas e exibidas como imagens.)
Nuvens de palavras são simples de entender e tendem a ser visualmente interessantes. Contudo elas podem ser problemáticas por várias razões: primeiro, porque o número de letras de uma palavra pode torna-la maior do que deveria; segundo, porque pode ser difícil distinguir visualmente duas palavras com frequências próximas. Compare “Car” com 17 menções, a “Newman” (com 14), onde o segundo parece muito maior que o primeiro.
Em contextos mais formais, vale mais a pena o uso de gráficos de barras ou lollipop. Como, por exemplo, a quantidade de vezes que os personagens mencionam “coffee”:
script %>%
unnest_tokens(word, Dialogue) %>%
filter(str_detect(word, "coffee|Coffee")) %>%
group_by(Character) %>%
tally() %>%
filter(Character %in% c("ELAINE", "GEORGE","JERRY","KRAMER")) %>%
ggplot(aes(x = fct_reorder(Character, n), y = n, color = Character)) +
geom_point(size = 8) +
geom_segment(aes(x=as.factor(Character), xend=as.factor(Character), y=0, yend=n),
size = 4) +
#geom_hline(yintercept = mean(df$Rating), linetype = 5, color = "grey10", size = 1) +
theme_ipsum(base_family = "Roboto") +
labs(title = "Seinfeld, Menções a Café por Personagem", y = "Menções", x = "Personagem",
caption = "Fonte: IMDb") +
theme(legend.position = "none") +
coord_flip()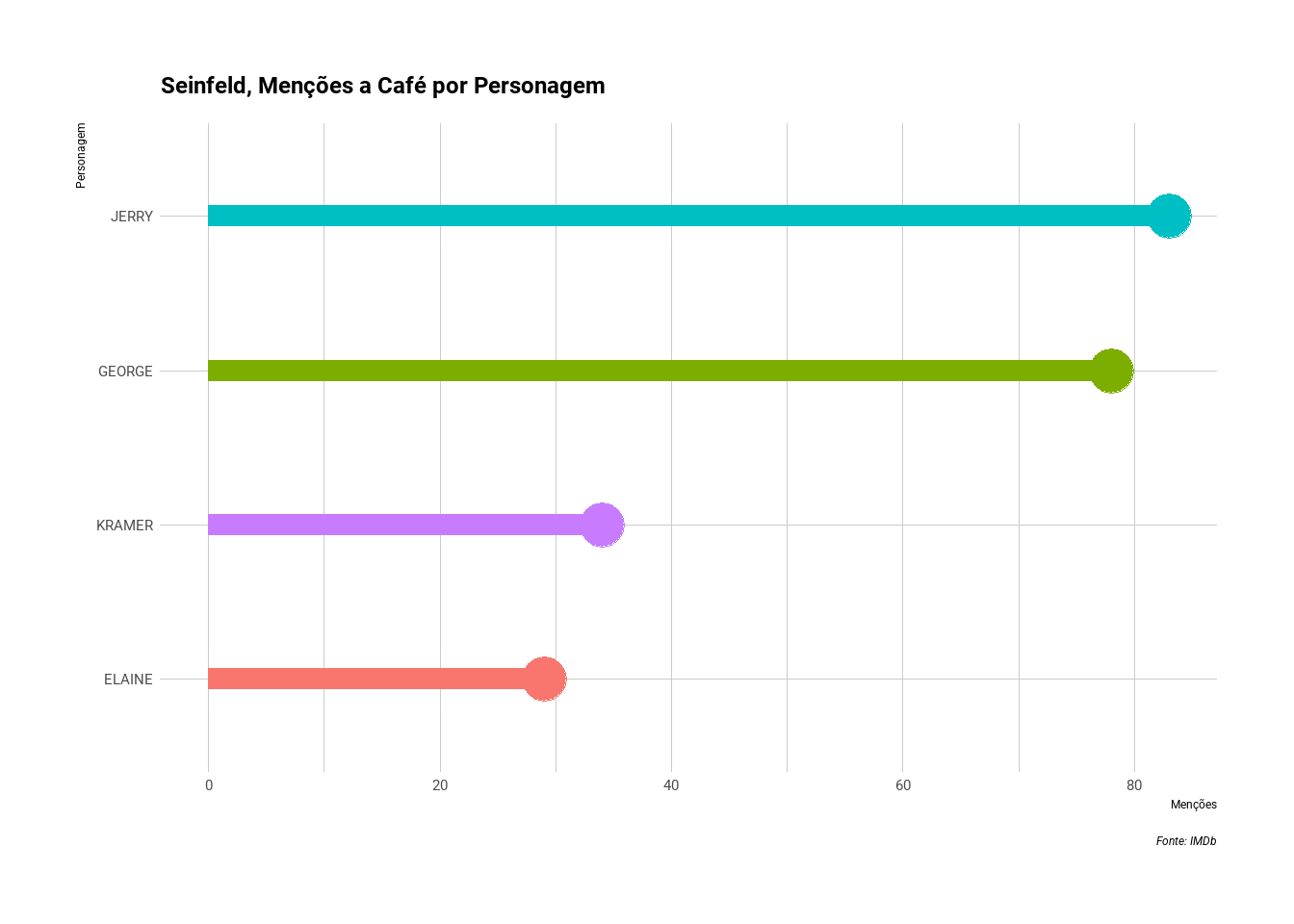
Correlação
Com os gráficos de correlação o objetivo é visualizar como duas ou mais variáveis se relacionam.
Gráfico de dispersão por temporada
Podemos utilizar um gráfico de dispersão de notas por temporada para verificar a relação entre temporada e notas dos episódios. Podemos observar se os epísodios se tornaram melhores com o passar do tempo.
df %>%
ggplot(aes(x = episode, y = Rating, color = as.factor(Season))) +
geom_point() +
geom_smooth() +
theme_ipsum(base_family = "Roboto", base_size = 24) +
labs(title = "Seinfeld, Notas dos Por Episódio", y = "Nota", x = "Episódio", color = "Temporada", caption = "Fonte: IMDb") +
geom_hline(yintercept = mean(df$Rating), linetype = 5, color = "grey2", size = 1) +
annotate("label", label = "Nota média: 8.4", x = 6, y = 9) +
#geom_label(aes(label = as.factor(Season))) +
theme(legend.position = "bottom")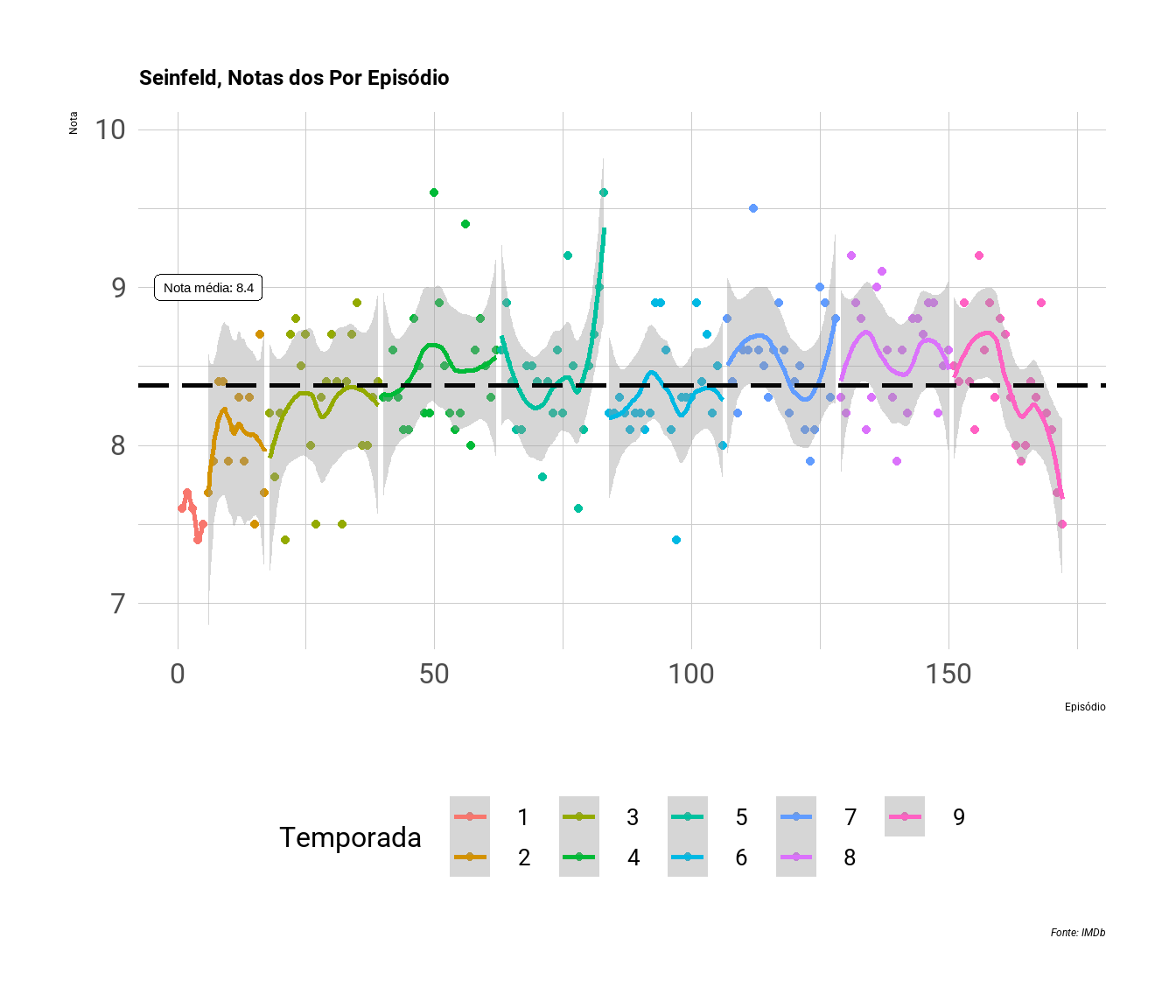
Acima usamos um gráfico de dispersão (geom_point) em conjunto com uma gráfico de tendência/ajuste (geom_smooth). Com eles observamos as notas dos episódios dentro de cada temporada.
Para facilitar a comparação, inclui uma linha tracejada com a nota média de toda a série (de 8,4), facilitando algumas comparações. Por exemplo, a primeira temporada foi consistentemente abaixo da média; a quinta temporada teve um final arrebatador; enquanto que as temporadas 6, 7 e 8 seguraram bem a qualidade. Já a final da última temporada parece ter desapontado a maioria dos fãs, ficando abaixo da média histórica.
Alternativamente, podemos estar interessados se existe uma relação entre o total de falas de cada personagem e a nota do episódio.
Para tanto, vamos unir a base de dialógicos com a base de notas por episódio:
aparicoes_episodio <- script %>%
group_by(SEID, Character) %>%
summarise(n = n()) %>%
filter(!is.na(Character))
aparicoes_notas <- df %>%
group_by(Season) %>%
mutate(Episode_Season = row_number()) %>%
ungroup() %>%
mutate(SEID = paste0("S", str_pad(Season, 2, pad = "0"),"E", str_pad(Episode_Season, 2, pad = "0"))) %>%
select(SEID, Rating, episode, Season) %>%
left_join(aparicoes_episodio, by = "SEID")
aparicoes_notas %>%
arrange(desc(n)) %>%
head() %>%
knitr::kable()| SEID | Rating | episode | Season | Character | n |
|---|---|---|---|---|---|
| S01E01 | 7.6 | 1 | 1 | JERRY | 250 |
| S04E03 | 8.6 | 42 | 4 | JERRY | 151 |
| S05E18 | 8.5 | 80 | 5 | JERRY | 149 |
| S04E20 | 8.8 | 59 | 4 | JERRY | 144 |
| S07E18 | 8.1 | 124 | 7 | JERRY | 137 |
| S02E09 | 8.3 | 14 | 2 | JERRY | 134 |
Agora podemos criar um gráfico para os principais personagens da série: Jerry, George, Elaine, Kramer, Newman, e os pais de Jerry (Morty e Helen), que são os personagens com mais falas na série.
personagens_mais_mencionados <- aparicoes_notas %>%
group_by(Character) %>%
summarise(falas = sum(n)) %>%
arrange(desc(falas)) %>%
top_n(falas, n = 7) %>%
pull(Character)
aparicoes_notas %>%
filter(!is.na(Character)) %>%
filter(Character %in% personagens_mais_mencionados) %>%
ggplot(aes(x = n, y = Rating, color = as.factor(Character))) +
geom_point() +
geom_smooth() +
guides(color = FALSE) +
facet_wrap(~Character, scales = "free_x", ncol = 2) +
theme_ipsum(base_family = "Roboto", base_size = 24) +
labs(y = "Nota", x = "Falas durante o episódio", title = "Seinfeld, Relação entre total de falas do personagem e Nota do Episódio", caption = "Fonte: IMDb") +
theme(legend.position = "none")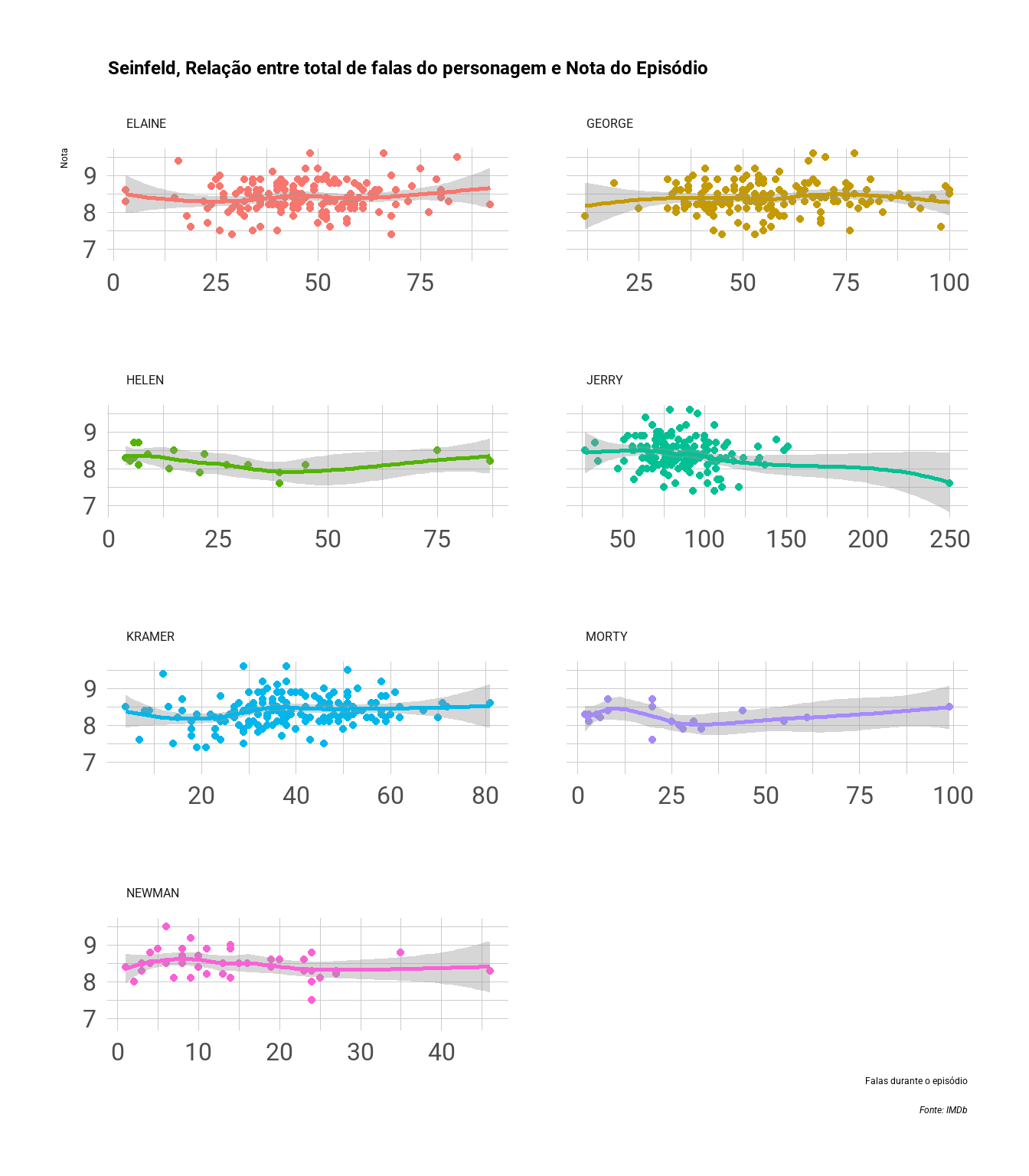
Jerry, George, Elaine e Kramer aparecem na grande maioria dos episódios, de modo que é difícil enxergar uma relação entre o total de falas do personagem e a nota dos episódios. Morty, Helen e Newman são personagens que surgem esporadicamente, então a adição ou não dos personagens poderia revelar algo mais interessante, mas também não parece ser o caso. Acredito que é uma boa notícia: a série é consistemente bem avaliada independente do elenco do episódio e do personagem em foco.
Gráfico de Calor
Os gráficos de anteriores são muito bons em mostrar o comportamento médio, mas se tivermos interessados em encontrar os melhores episódios individuais podemos utilizar visualizações como o gráfico de calor (ou heatmap).
Gráficos de calor são uma boa alternativa para identificar outliers, como episódios muito acima da média. A figura abaixo mostra 4 destes episódios (em amarelo). Podemos também idenficar aqueles episódios que deixaram a desejar, buscando os pontos mais escuros do gráfico (como o final da última temporada e episódio 4 da terceira temporada).
df %>%
group_by(Season) %>%
mutate(Episode_Season = row_number()) %>%
ungroup() %>%
ggplot(aes(x = Episode_Season, y = as.factor(Season), fill = Rating)) +
geom_tile() +
scale_fill_viridis() +
theme_ipsum(base_family = "Roboto") +
labs(title = "Seinfeld, Notas por Episódio",
y = "Temporada", x = "Episódio", color = "Temporada", caption = "Fonte: IMDb", fill = "Nota:") +
theme(legend.position = "bottom")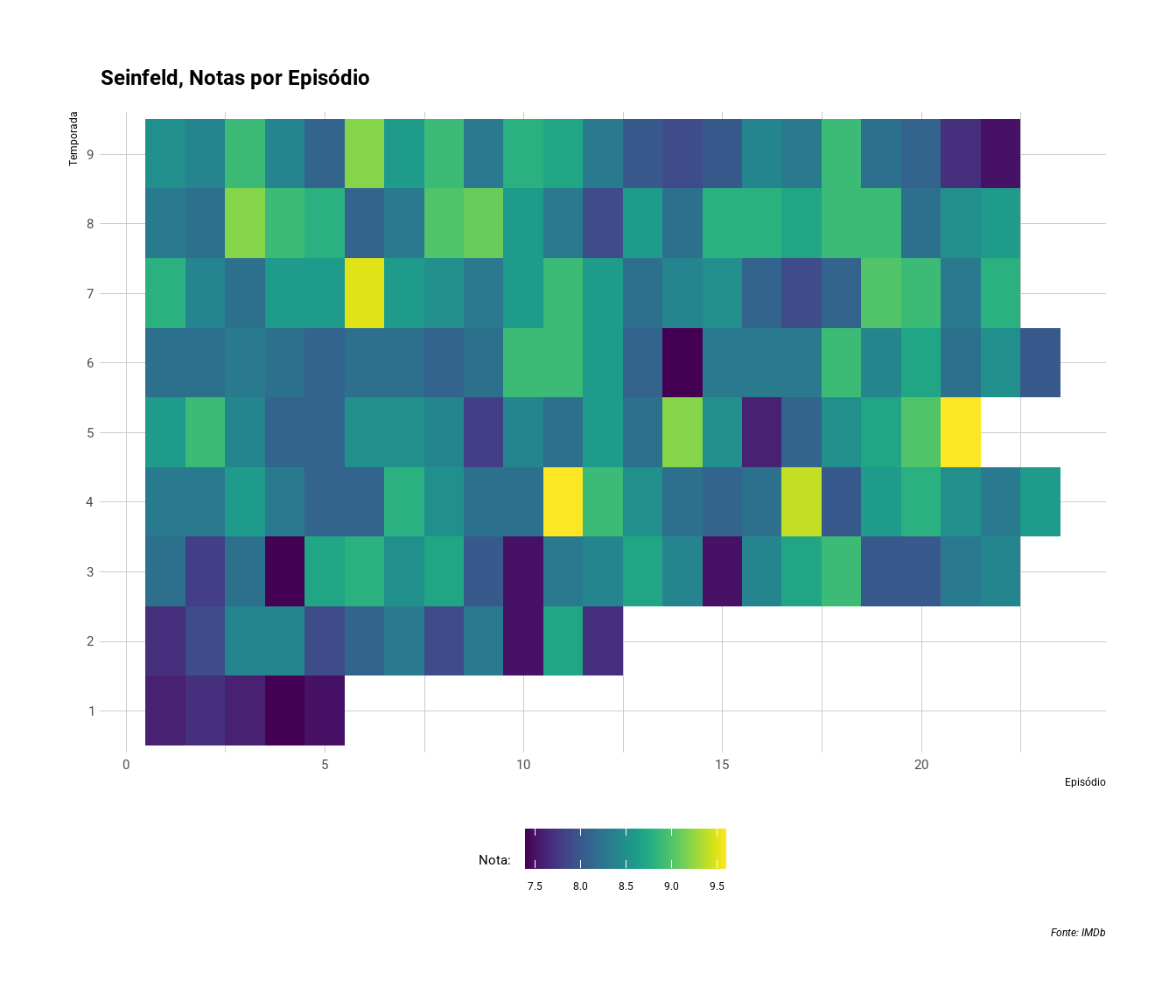
Se bateu a curiosidade para saber quais são os melhores episódios, segue a lista abaixo:
df %>%
group_by(Season) %>%
mutate(Episode_Season = row_number()) %>%
ungroup() %>%
slice_max(order_by = Rating, n = 4) %>%
select(Episode_Season, Season, Title, Rating) %>%
knitr::kable()| Episode_Season | Season | Title | Rating |
|---|---|---|---|
| 11 | 4 | The Contest | 9.6 |
| 21 | 5 | The Opposite | 9.6 |
| 6 | 7 | The Soup Nazi | 9.5 |
| 17 | 4 | The Outing | 9.4 |
Gráficos de Distribuição
Quando o objetivo é visualizar a distribuição de uma variável, podemos sempre recorrer ao bons e velhos histograma (geom_histogram), gráficos de densidade (geom_density) ou boxplot (geom_boxplot). Ou podemos ser mais criativos, utilizando o gráfico de violino (geom_violin) e o ridgeline (ggridges::geom_density_ridges).
Histograma
Sem muito segredos, o histograma mostra a frequência de falas ao longo dos episódios. Como as notas representam dados contínuos, podemos separar os valor por faixas de valores (bins = 10). Nenhuma surpresa, Jerry e George tem bem mais falas em média que Kramer e Elaine. Newman aparece esporadicamente, mas sempre com pequenas participações (no máximo 40 falas). Enquanto que Helen e Morty, por serem um casal, possuem distribuições bem próximas, mas exibindo, alguns episódios com elevada presença (100 falas no caso de Morty).
aparicoes_notas %>%
filter(Character %in% personagens_mais_mencionados) %>%
ggplot(aes(x = n, fill = Character)) +
geom_histogram() +
facet_wrap(~Character, scale = "free_x", ncol = 2) +
theme_ipsum(base_family = "Roboto", base_size = 24, plot_title_size = 24) +
labs(title = "Seinfeld, Fala dos Personagens", y = "", x = "") +
theme(legend.position = "none")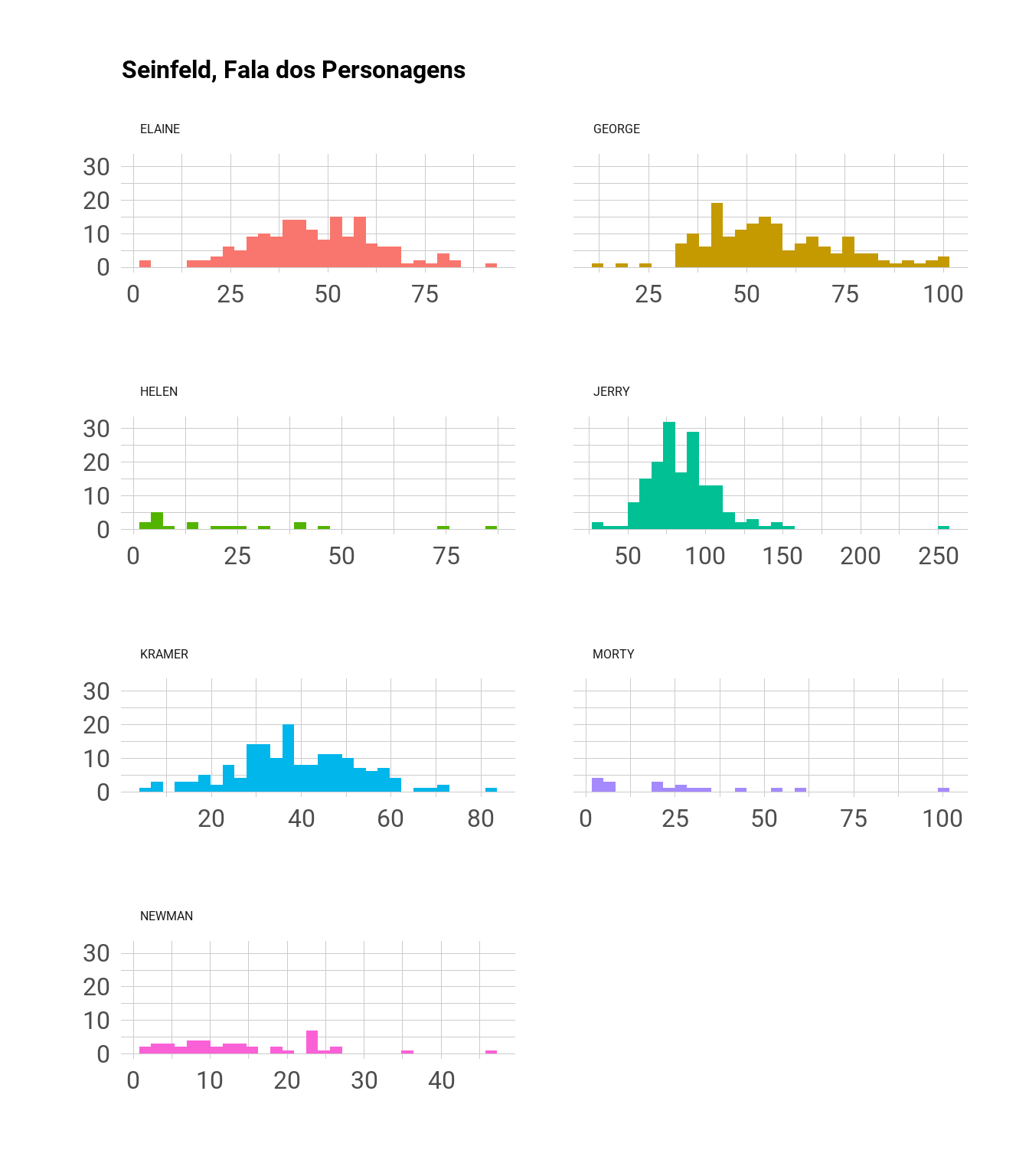
Gráfico de densidade
Alternativamente ao histograma, outro gráfico de densidade é a densidade kernel. Podemos exibir seu uso com uma distribuição simples de notas por temporada. Da mesma forma que no histograma acima, podemos mostrar a densidade de cada temporada como uma faceta (facet_wrap), ou podemos ser criativos e usar um ridgeline. Esta última permite exibir densidades por grupos em uma mesma visualização, com um visual bem charmoso de montanha.
df %>%
ggplot(aes(x = Rating, y = as.factor(Season), fill = ..x..)) +
geom_density_ridges_gradient(scale = 3, rel_min_height = 0.01) +
scale_fill_viridis(name = "Nota", option = "C") +
labs(title = "Seinfeld, Nota por Temporada", y = "Temporada", x = "Nota", caption = "Fonte: IMDb") +
theme_ipsum(base_family = "Roboto", base_size = 24) +
theme(legend.position = "none",
panel.spacing = unit(0.1, "lines"))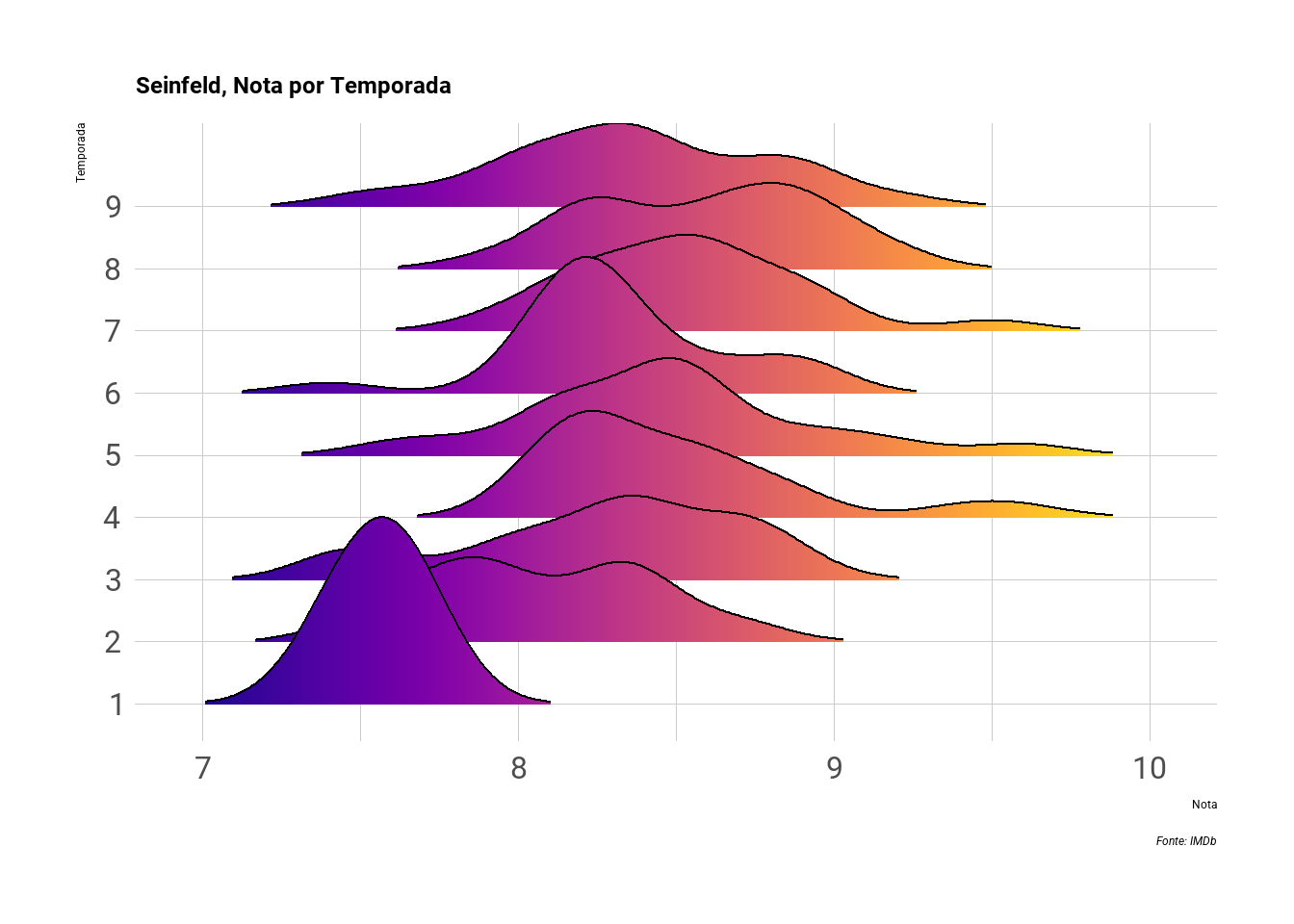
Boxplot
Boxplot (ou diagrama de caixas) é um gráfico bem completo, pois exibe de uma vez só a nota mediana por temporada, a amplitude interquartil e os valores discrepantes.
Como o gráfico de calor, ele permite identificar episódios que se destacaram positivamente, como os 4 discutidos acima, ou negativamente, como um dos episódios da 6ª temporada, que ficou bem abaixo da média da temporada.
O boxplot ainda exibe a amplitude interquartil, o que nos permite avaliar o quão consistente uma temporada é, como a quinta e a última temporada, que teve altos e baixos.
df %>%
ggplot(aes(x = Rating, y = as.factor(Season), fill = as.factor(Season))) +
geom_boxplot() +
#facet_wrap(~Season) +
theme_ipsum(base_family = "Roboto", base_size = 24) +
labs(title = "Seinfeld, Notas por Temporada", y = "Temporada", x = "Nota",
caption = "Fonte: IMDb") +
theme(legend.position = "none") +
coord_flip()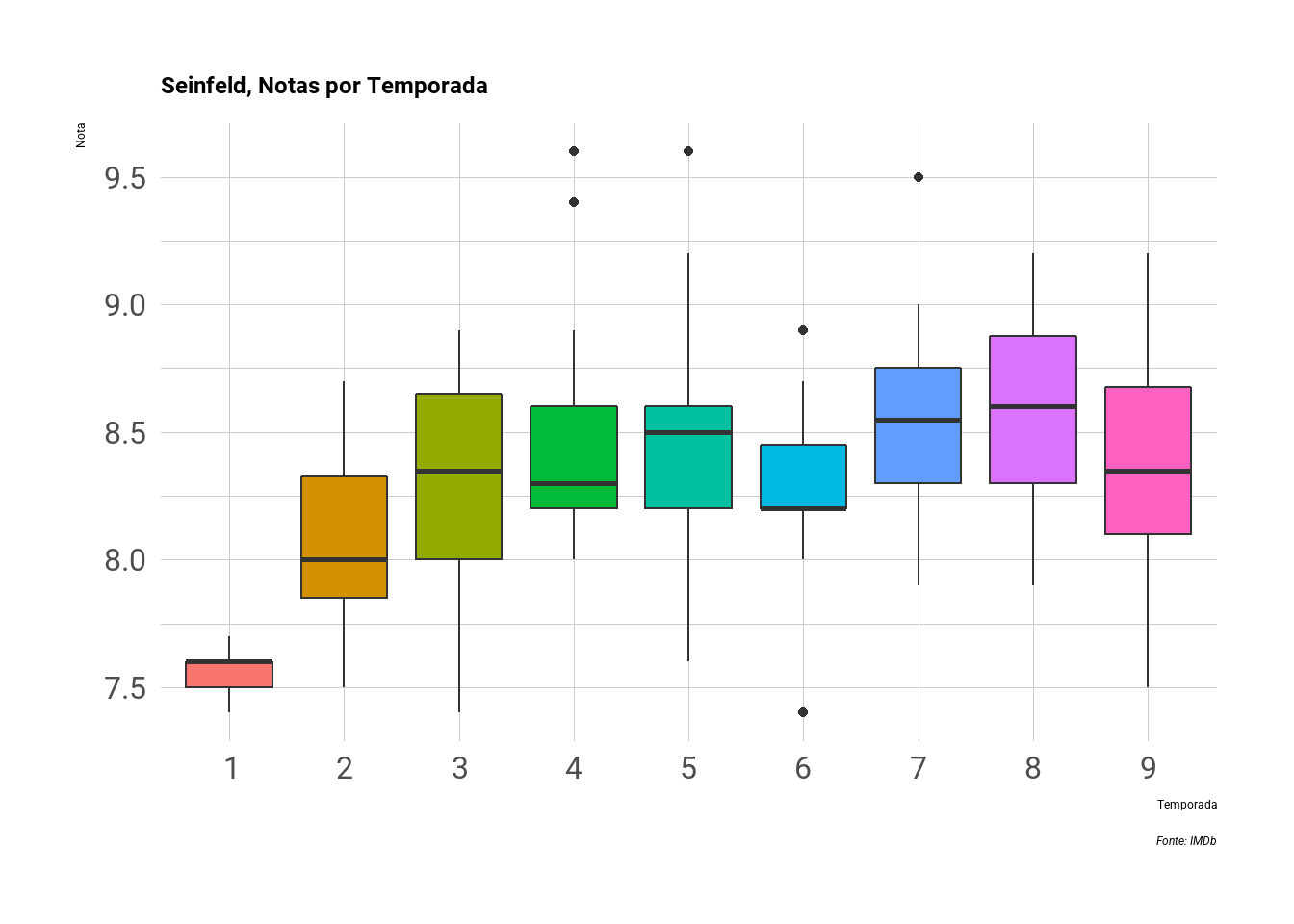
A mesma visualização de boxplot pode ser usada para exibir o total de falas por episódio. Para não repetir o mesmo tipo de informação, vamos construir o total de falas por cada temporada.
aparicoes_notas %>%
filter(Character %in% c("JERRY", "GEORGE", "ELAINE", "KRAMER")) %>%
ggplot(aes(x = n, y = Character, fill = Character)) +
geom_boxplot() +
theme_ipsum(base_family = "Roboto", base_size = 24) +
labs(title = "Seinfeld, Fala dos Personagens por Temporada", y = "", x = "") +
theme(legend.position = "none") +
facet_wrap(~Season, scale = "free_y") 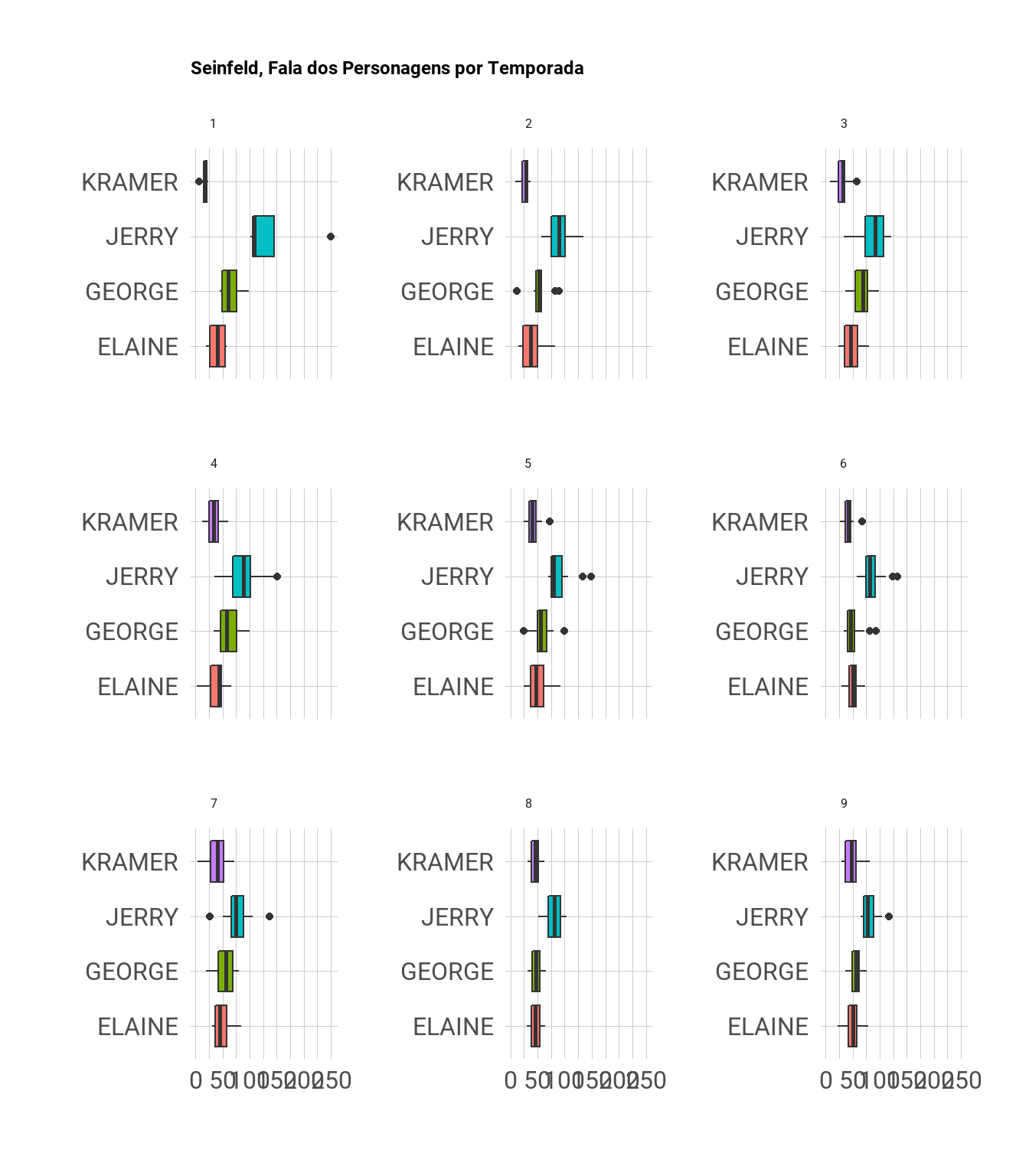
É possível notar que Jerry consistentemente possui mais falas ao longo das 9 temporadas da série, enquanto que a participação dos demais é mais balanceada, principalmente a partir da sexta temporada.
Podemos repetir a mesma visualização pra os personagens secundários, mas agora utilizando um gráfico de violino. A interpretação desse gráfico é a mesma do gráfico boxplot (ele exibe mediana, e o 1º e 3º quartis, além de valores discrepantes).
É possível notar que apenas a partir da terceira temporada esses personagens se tornaram peça recorrente da série, com destaque para a quinta temporada.
aparicoes_notas %>%
filter(Character %in% c("MORTY", "HELEN", "NEWMAN")) %>%
ggplot(aes(x = n, y = Character, fill = Character)) +
geom_violin() +
theme_ipsum(base_family = "Roboto", base_size = 24) +
labs(title = "Seinfeld, Fala dos Personagens por Temporada", y = "", x = "") +
theme(legend.position = "none") +
facet_wrap(~Season, scale = "free_y", ncol = 2) 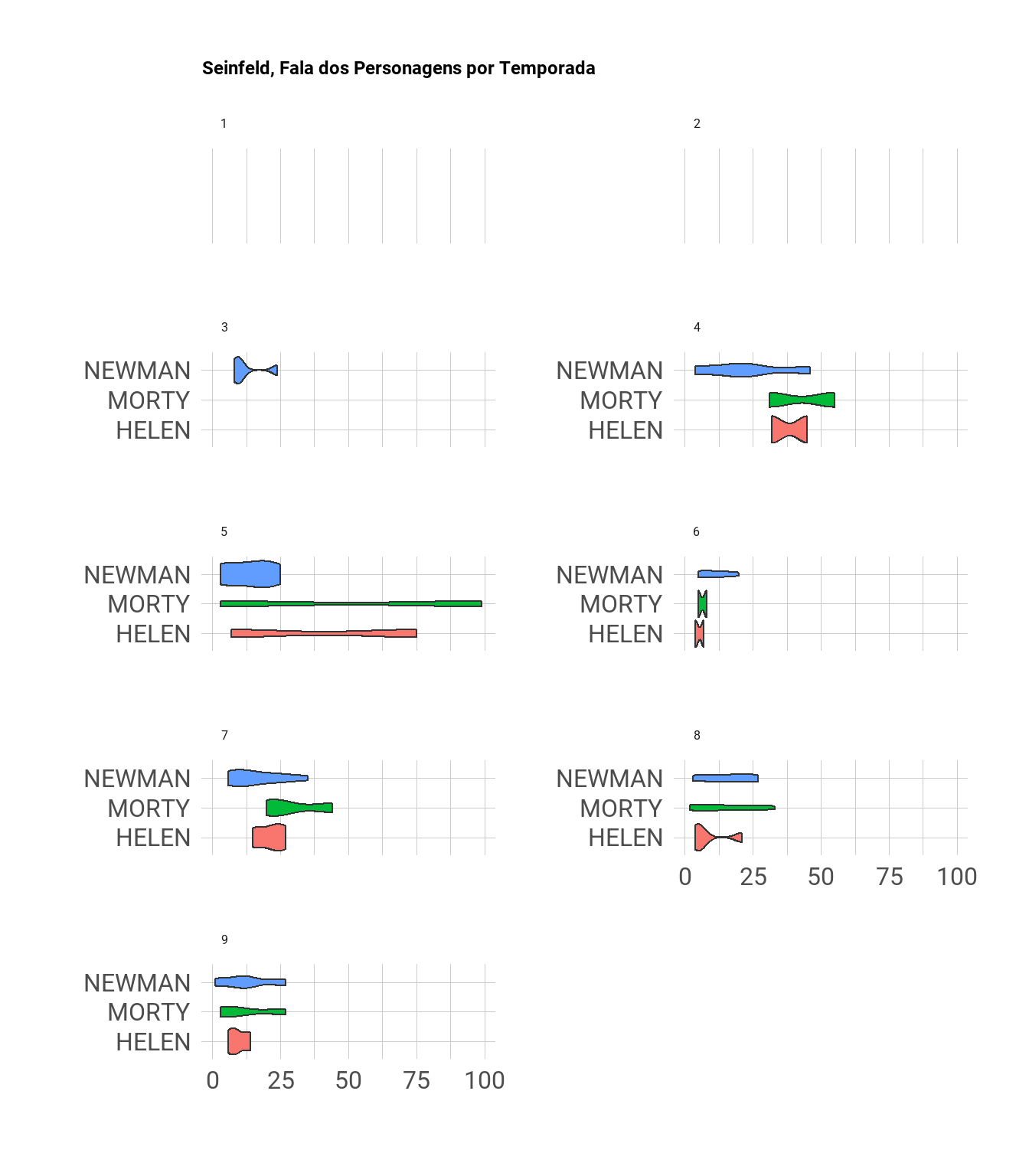
Conclusão
O ggplot2 é um pacote de visualização bem robusto no R. Ele ainda oferece uma infinidade de outros tipos de visualizações, mas aqui foquei nas principais visualizações, e aquelas que os dados permitiam produzir.
Para além do ggplot2, uma série de extensões foram desenvolvidas pela comunidade, o que permite a criação de praticamente qualquer visualização imaginada, o que inclui criar gráficos com temas do Bob Sponja.